April, 2024
Gustavo M. Santana, Marcelo O. Dietrich
https://www.biorxiv.org/content/10.1101/2024.04.19.590368v1
https://github.com/gumadeiras/squeakout
0. Abstract
- 쥐는 social communication에 중요한 USVs (Ultrasonic Vocalizations)를 방출함
- noise 제거 등의 spectrograms에서 USV를 정확하게 segmentation하는 것이 아직 challenge로 남아있음
- 12,954개의 dataset(명시적으로 USV segmentation에 대해 주석이 달린 spectrograms)을 사용해서 SqueakOut을 개발 (USV의 spectrograms의 supervised segmentation에서 Dice score가 90.22로 높은 accuracy를 가진 lightweight (4.6M parameters) fully convolutional autoencoder)
- MobileNetV2 backbone에 skip connections와 transposed convolution을 결합해서 USV를 정밀하게 segment
- stochastic data augmentation technique과 hybrid loss function을 사용해 다양한 recording 조건에서 robust한 segmentation을 학습
- VocalMat(Dice score 63.82)보다 높은 Dice score 보임
- SqueakOut을 통한 정확한 segmentation 결과는 새로운 vocalization classification을 가능하게 하고 쥐의 communication 분석을 정확하게 함
- 12,954 spectrogram USV segmentation dataset과 the SqueakOut implementation 공개함
1. Introduction
USV의 의미
- 동물들에게 vocalization은 중요한 social communication 수단으로, 쥐는 maternal interactions, social exploration, courtship, distress situations (e.g., maternal separation)과 같은 상황에서 ultrasonic vocalizations (USVs)를 내고 이는 사람이 들을 수는 없지만 많은 정보 (e.g., internal state, behavioral experience) 를 전달함
- e.g., 새끼 쥐가 어미로부터 분리될 때 내는 USV는 어미의 maternal behavior를 유발하고 어미의 뇌에서 특정 pathways를 활성화함
- USV를 자세히 분석하면 neurodevelopmental disorders, genomic imprinting, pharmacological manipulations와 같은 다양한 mouse model의 phenotype을 연구하거나 다른 설치류 종들과 비교 연구하기에 좋음
⇒ vocalization은 동물의 internal state를 들여다 볼 수 있게 하고 동물의 행동과 뇌 기능을 이해할 수 있게 도움
USV 분석의 challenges
- 정확한 spectrotemporal features를 추출하는 것의 complexity
- 문제의 3가지 요소; detection, classification, segmentation
1. Detection
- 실제 vocalization signal에서 silence나 noise를 구분하는 과정 (figure 1A)
- USV 분석의 신뢰성, 타당성을 좌우해서 중요한 과정임
2. Classification
- acoustic features나 specific characteristics를 기반으로 detected USVs는 다른 class로 분류하는 과정
- 비슷한 소리를 같은 그룹으로 분류해서, 다양한 맥락에서의 USV의 다양성과 분포를 공부하는 데 도움이 됨
3. Segmentation (figure 1B)
- detected USV를 각 spectrotemporal unit으로 잘게 쪼개는 과정
- segmentation을 통해 각 vocalization의 구조에 대한 자세한 분석이 가능함
전통적인 USV 분석 방법
- manual annotation이나 predefined parameters와 threshold에 기반한 semi-automated techniques에 의존
- 대규모 dataset이나 복잡한 vocalization repertories를 다루기에 좋지 않음 (labor-intensive, time-consuming, bias와 error에 취약함)
- USV에 내재된 미세한 spectrotemporal variations을 포착하는 데 실패하기도 함
최근의 USV 분석 연구
- Computer Vision이나 Machine Learning model을 적용한 data-driven alternative를 모색
- CNN 구조는 USV detection와 분류에 좋은 성능을 보였지만, spectrogram에서 정확히 segmentation하지 못하는 한계가 있음
SqueakOut
- 쥐의 USV segmentation을 위해 특별히 설계된 ML dataset을 사용
- SqueakOut이라는 fully convolutional autoencoder를 사용해 정확한 USV segmentation을 가능하게 함
- SqueakOut의 성능을 VocalMat과 비교하고, segmentation된 USV가 downstream analysis task에서 유용함을 입증
- high-throughput USV phenotyping workflow에의 잠재적 응용 가능성을 논의

2. Results
2.1 Creating a USV segmentation dataset
- automated and manual 접근법을 결합해서 segmentation dataset을 생성
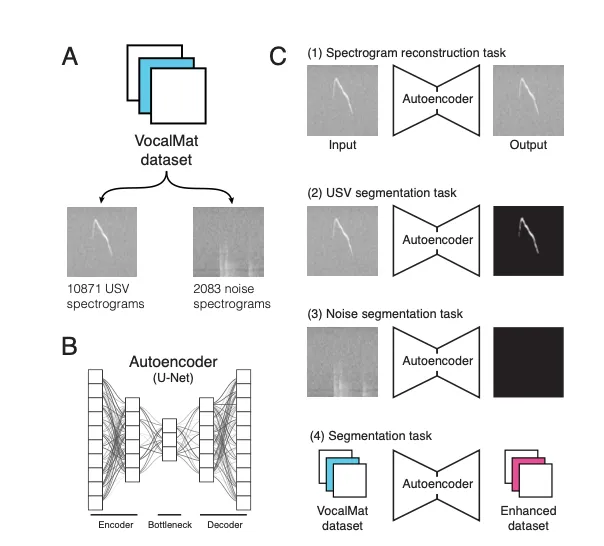
- VocalMat에서 제공하는 공개 dataset을 시작점으로 사용(Figure 2A)
- 12,954 spectrograms including 2,083 noise spectrograms and 10,871 mouse USVs spectrograms
- 수컷, 암컷 모두 포함하고 있고, 생후 5일에서 15일 사이의 5가지 생쥐 계통 (C57Bl6/J, NZO/HlLtJ, 129S1/SvImJ, NOD/ShiLtJ, PWK/PhJ) 포함
2.1.1 Automated approaches for creating a USV segmentation dataset
- VocalMat은 USV detection에서 높은 성능을 보이지만, noise가 있는 spectrograms에서 segmentation 성능이 낮아 segmentation neural network를 학습하기에 적합하지 않음(Figure 3C)

- VocalMat의 segmentation masks를 시작점으로 해서 autoencoder를 train해 segmentation 과정을 학습시킴
- autoencoder는 USV와 noise spectrogram에 대해 개별적으로 train되어서, 원래의 segmentation masks를 denoising할 수 있음
Automated Processing Steps: noise segment가 감소된 vocalization segmentation masks를 포함한 여러 dataset을 생성
1. Unsupervised Spectrogram Reconstruction Task
- U-Net autoencoder(Figure 2B)를 사용해 VocalMat dataset에서 unsupervised 방식으로 spectrogram을 복원함(Figure 2C-1)

- 이 과정에서 autoencoder는 spectrogram을 입력받아 동일한 spectrogram을 출력으로 재구성하도록 train되었음
- bottleneck architecture를 사용하여 단순히 입력을 복사하지 않고 데이터의 의미 있는 표현을 학습할 수 있음
- reconstruction accuracy: 평균 91.67% ± 2.08% (매우 높음)
2. USV Segmentation Task
- pre-trained autoencoder를 사용해 USV segmentation(Figure 2C-2)

- autoencoder의 input: USV spectrogram, output: binary segmentation(0과 1로 구성된 image; 1은 USV 구간을 의미)
- VocalMat이 생성한 segmentation mask를 학습의 초기 정답 레이블(ground truth annotation)로 사용
3. Noise Segmentation Task
- 이전 단계와 유사하게 autoencoder를 noise spectrogram만을 사용해 segmentation 작업을 수행하도록 훈련(Figure 2C-3)
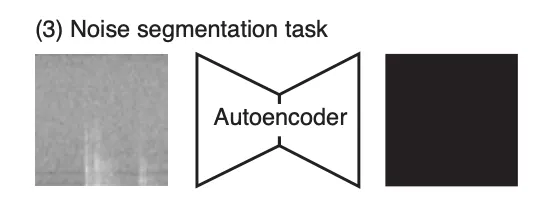
- autoencoder가 spectrogram에서 노이즈와 실제 발성을 구분하는 표현을 학습하게 됨
4. Enhancing the Dataset
- pre-training을 완료하고, autoencoder를 사용해 VocalMat dataset에 대해 segmentation 추론(Figure 2C-4)
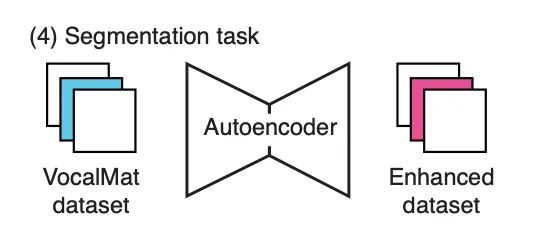
- autoencoder는 VocalMat과 유사한 segmentation mask를 생성했지만, false positives이 적은 결과를 제공함
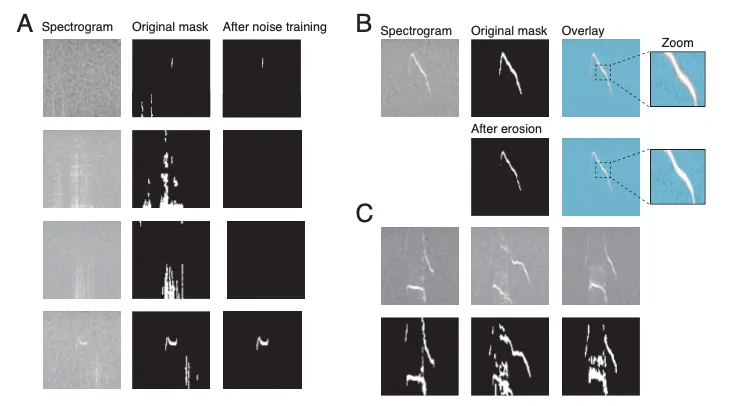
- e.g., 노이즈만 포함된 spectrogram에서 VocalMat의 Dice 점수는 2.85% ± 1.27%였으나, autoencoder는 78.91% ± 4.86%로 성능이 크게 개선됨(Figure 3A)
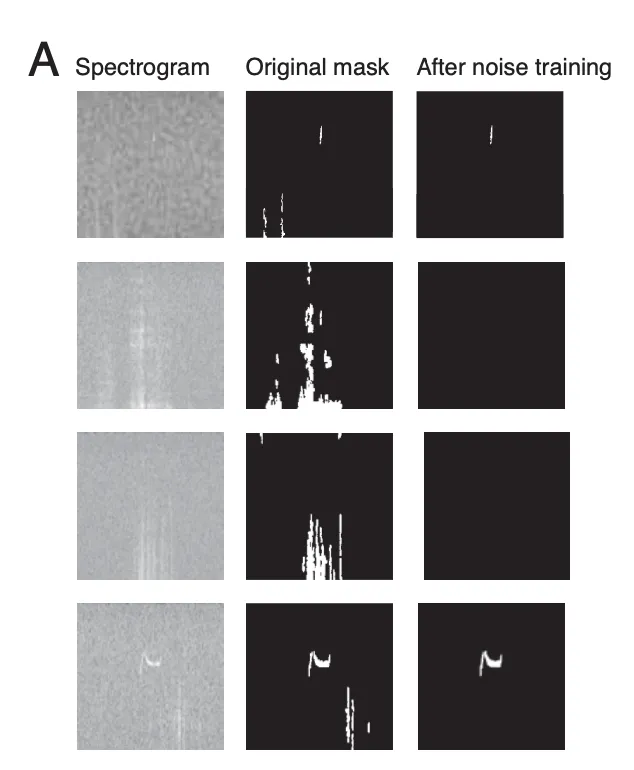
2.1.2 Manual fine-tuning of the USV segmentation dataset
- 자동화 단계를 통해 원본보다 개선된 dataset을 생성했지만, fine-tuning이 필요
- VocalMat은 실제 vocalization 크기를 초과하여 vocalization과 주변 pixel을 모두 캡처(=border effect)하는 segmentation mask를 생성 (Figure 3B)
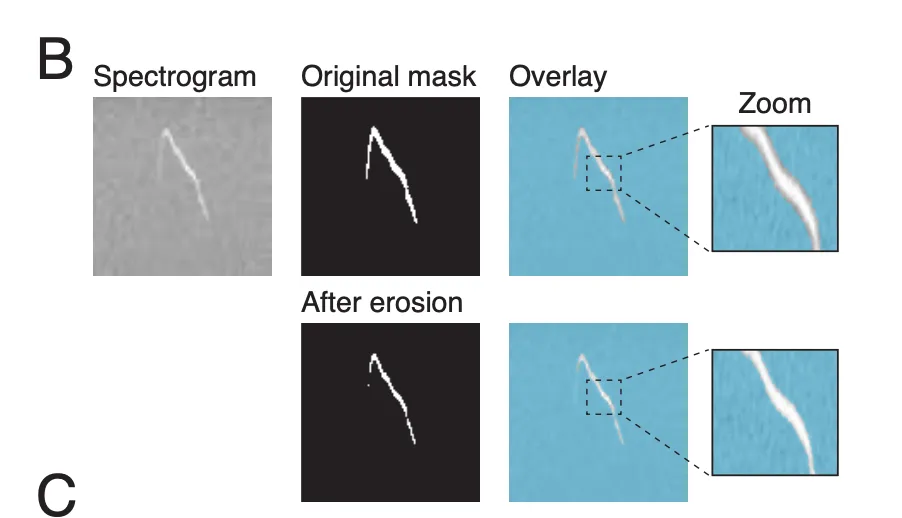
Border Effect Mitigation (경계 효과 해결)
- erosion (morphological image processing technique) 사용해 border effect 감소시킴
- thinning을 통해 segmentation mask의 크기를 줄여 border effect를 완화(Figure 3B)
- 이미 작은 vocalization segment가 지나치게 줄어들지 않도록, erosion kernel(4x2 pixels)보다 최소 4배 큰 vocal segment에만 erosion을 적용
- erosion이 완료된 후 앞서 진행한 automated and manual refinement에서 USV segmentation task, Noise segmentation task, Enhancing dataset 과정을 반복해서 적용
- 더 이상 erosion을 적용할 수 없을 때까지
Final Manual Refinement
- VocalMat dataset에서 2,000개 이상의 noise 예제가 포함되었지만, 일부 유형의 noise는 vocalization을 포함한 spectrogram에만 존재
- 이러한 noise segment는 vocalization으로 잘못 detection 될 수 있어(Figure 3C), 전문가가 segmentation mask를 검토하고 RectLabel tool을 사용해 약 15%의 데이터를 수정했음
+) Figure 2, 3
2.2 SqueakOut: Autoencoder for mouse USV segmentation
2.2.1 Network architecture
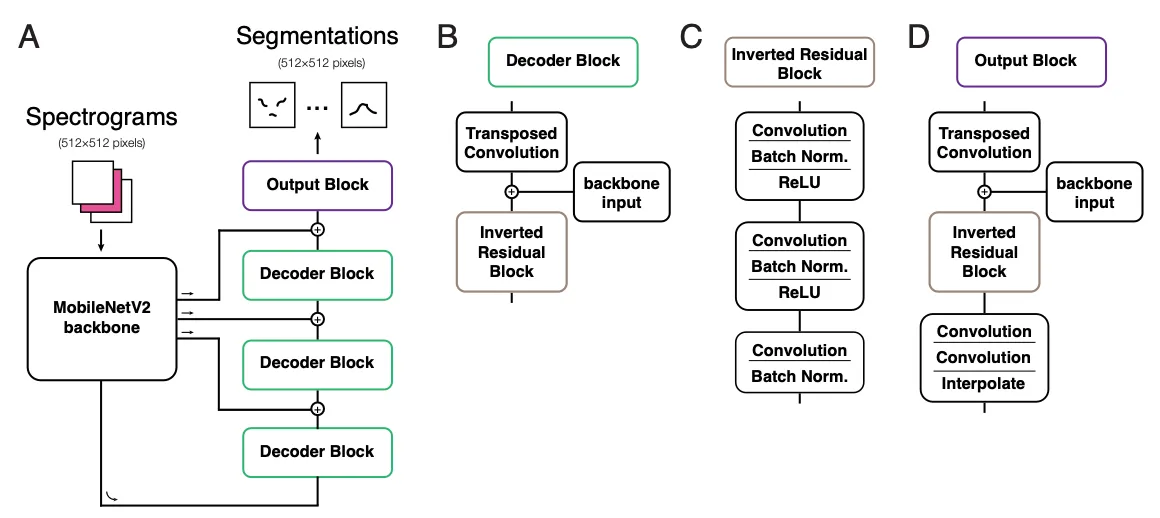
- spectrogram에서 발성의 segmentation mask를 생성하는 fully convolutional autoencoder
- backbone: MobileNetV2
- MobileNetV2의 장점: 작은 메모리 사용량과 효율적인 처리 속도
- inverted residuals, depth-wise convolution, 그리고 좁은 layer에서의 비선형성을 제거한 구조 때문 (average pooling layer를 제거하고, 최종 bottleneck layer 이전에 dropout layer(20% 비율)를 추가)
- MobileNetV2의 장점: 작은 메모리 사용량과 효율적인 처리 속도
- decoder
- backbone layer에서의 skip connection과 transposed convolution을 사용하여 segmentation mask를 reconstruction하는 역할
- skip connection:segmentation accuracy를 높이고, 세부적인 정보를 포착하는 데 도움을 주고, gradient propagation과 convergence 속도를 개선
- backbone layer에서 나온 input을 decoder path의 이전 layer output과 concatenation하여 초기 레이어의 정보를 유지하도록 설계
- output block에서는 일련의 convolution layer와 interpolation을 사용해 output을 upsample하여 원본 spectrogram과 동일한 공간적 크기로 복원함
+) Figure 4 (SqueakOut Architecture)
2.2.2 Training
- PyTorch와 PyTorchLightning을 사용해 구현
- 개선된 VocalMat dataset에서 학습
- dataset의 일부(849개의 USV)는 testset으로 사용되었고, 나머지 data는 training(90%)과 validation(10%)으로 random하게 분리
- Adam optimizer를 사용
- learning rate = 1e-4
- validation 성능이 연속 5회 개선되지 않으면 learning rate을 0.1로 감소시키고, 성능이 연속 15회 개선되지 않을 경우 학습을 중단하여 overfitting을 방지
- batch size = 8
- Loss function: Focal loss(FL)와 Dice loss(DL)의 weighted sum으로 구성된 hybrid loss를 사용
- Focal loss: 어려운 data point에 집중하며, 쉬운 negative data가 loss를 지배하는 것을 방지
- Dice loss: network output과 ground-truth segmentation 간의 유사성을 측정
- hybrid loss를 사용한 이유: segmentation 작업에서 class간 label imbalance가 심해서(평균적으로 spectrogram의 대부분의 픽셀은 background를 나타내며, USV는 5% 미만의 픽셀만 차지함)
- Dice loss 계산 시 분모가 0이 되는 것을 방지하기 위해 ε 을 추가했음)
- γ = 2,α = 0.3을 사용
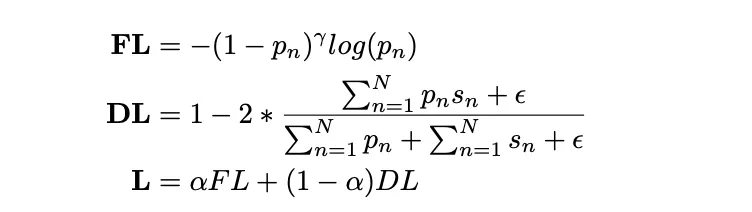
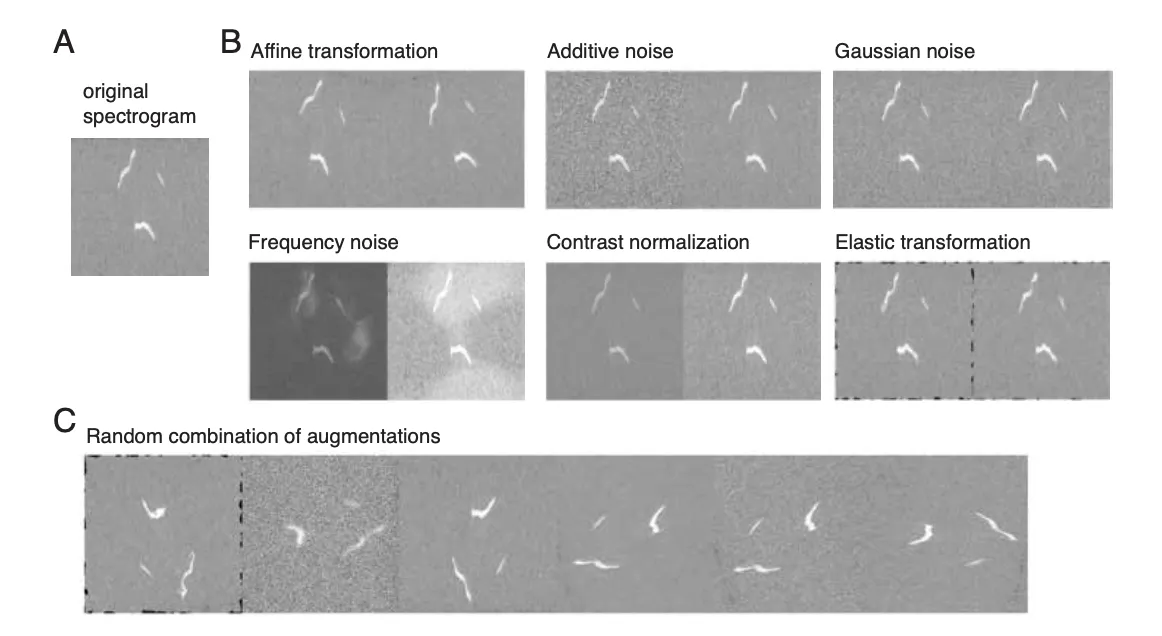
2.2.3 Data augmentations
- 목적: 다양한 형태와 품질의 spectrogram에 대해 잘 일반화할 수 있도록
- spectrogram에 적용된 증강이 동일하게 해당 segmentation mask에도 적용될 수 있다
- 이는 classification 작업에서는 적용되지 않음
- e.g., spectrogram이 무작위로 변형(warp)되어 USV의 형태적 특징이 변한다면, 해당 USV의 classification도 예측할 수 없는 방식으로 바뀔 가능성이 높기 때문
- SqueakOut의 견고성을 강화하고, spectrogram 품질의 변화에도 잘 일반화되도록 하기 위해 다음의 Data augmentation 기법을 사용
- 증강은 학습 중 batch 단위로 다음 조건에 따라 적용되고, 각 조건은 서로 독립적인 확률로 주어진 batch에 적용 (각 배치마다 아무런 증강이 적용되지 않을 수도 있고, 네 가지 증강이 동시에 적용될 수도 있음)
- (a) 75% 확률로 무작위 affine 변환(random affine transformation) 적용
- (b) 25% 확률로 contrast normalization 적용
- (c) 25% 확률로 Gaussian blur 적용
- (d) 33% 확률로 다음 중 하나를 적용: Additive noise / Gaussian noise / Frequency noise / Elastic transformations
- 증강은 학습 중 batch 단위로 다음 조건에 따라 적용되고, 각 조건은 서로 독립적인 확률로 주어진 batch에 적용 (각 배치마다 아무런 증강이 적용되지 않을 수도 있고, 네 가지 증강이 동시에 적용될 수도 있음)
- 효과: 학습 데이터의 다양성을 높이고, 입력 spectrogram의 변화에 대한 SqueakOut의 robustness를 향상
- e.g., noise와 contrastive augmentation은 낮은 signal-to-noise-ratio (signal 대 noise비)의 spectrogram에서 segmentation 성능을 향상시킴
- e.g., affine과 elastic transformation은 data에 포함되지 않은 USV 형태에 대해 모델의 robustness을 강화하고, USV 윤곽(contour) segmentation 품질을 개선
2.3 USV segmentation performance
- model size: 18MB (4.6M parameters) → fast and high accuracy
- 512×512 pixels의 spectrogram 64개 batch를 inference하는 데 gaming GPU에서는 0.035초 미만, CPU에서는 약 8초가 소요
Segmentation의 class label(0 또는 1) imbalance
- spectrogram에서 vocalization은 일반적으로 작기 때문에, 대부분의 픽셀은 배경(0)으로 분류됨
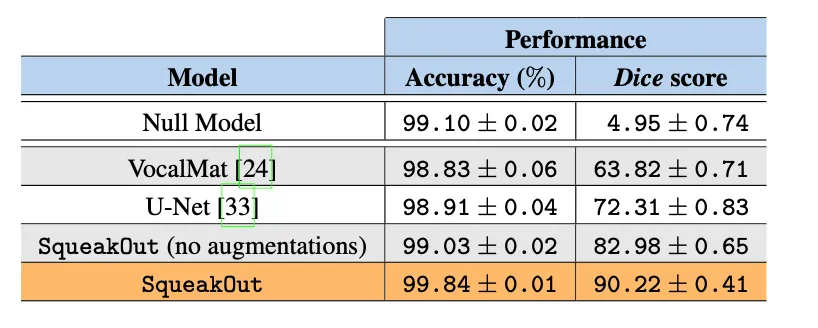
- 모든 spectrogram에 USV가 없다고 가정하고(blank segmentation mask: 모든 값이 0) 항상 빈 세분화 마스크를 생성하는 null 모델을 생성했더니, 99.09%의 pixel accuracy를 달성( = 대부분의 픽셀이 실제로 배경임)
- 그러나 null 모델의 Dice score는 4.95에 불과함
- Dice score: 두 segmentation mask 간의 겹침 정도를 측정하며, 교집합을 합집합에 대해 가중 평가(Equation 2)
- Dice score = 100; 완벽한 겹침
- FP와 FN 비율을 균형 있게 평가
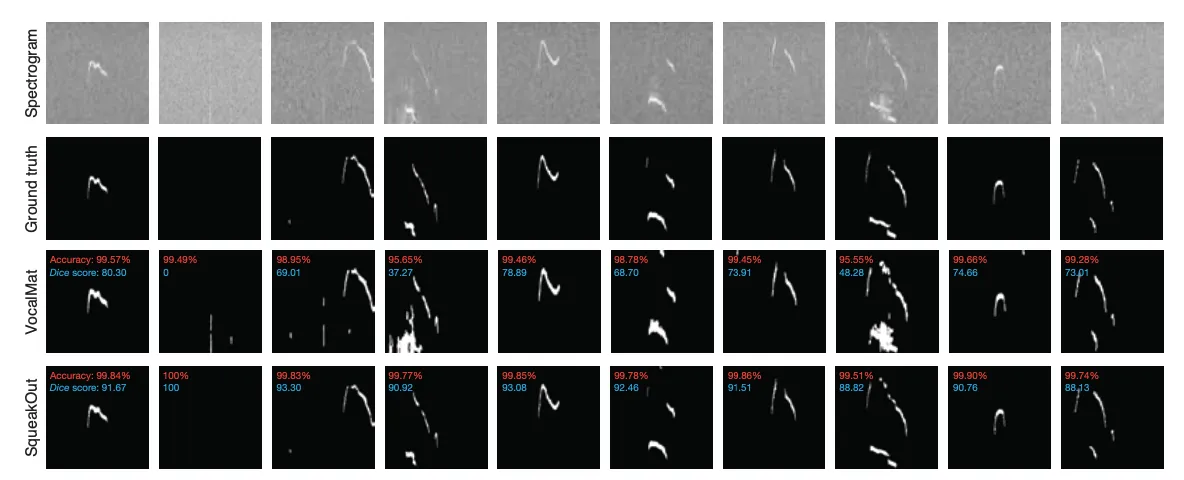
SqueakOut vs. VocalMat
- VocalMat은 spectrogram에서 high-intensity 구간을 포함한 모든 구간(노이즈 포함)을 segmentation하는 데 정확하지만(Figure 6), 이로 인해 Dice 점수가 상당히 낮음
- noise가 없으면 VocalMat의 성능이 SqueakOut과 질적으로 유사할 것으로 예상됨
SqueakOut vs. U-Net
- U-Net은 SqueakOut보다 낮은 성능을 (Table 1)
⇒ SqueakOut의 높은 Dice score가 단순히 정제된 dataset 덕분이 아니라, model architecture 자체에도 기인함
Data augmentation의 효과
- SqueakOut의 data augmentation은 Dice 점수를 8.72% 향상시켰습니다(Table 1)
⇒ data augmentation이 SqueakOut의 성능을 개선하는 데 중요한 역할을 했음
+) Figure 5
+) Figure 6
+) Table 1
3 Discussion
1. 새로운 쥐 USV segmentation dataset 소개
- 독특한 데이터셋을 활용해 SqueakOut을 개발하여 USV spectrogram의 supervised learning 기반의 segmentation를 수행, 높은 accuracy로 segmentation에 성공
- VocalMat dataset과 결합해서 쥐 USV detection 및 segmentation를 위한 single high-quality annotated dataset을 제공2.
2. autoencoder vs. supervised learning
- autoencoder는 annotated dataset없이 unsupervised learning 방식으로 latent data structure를 학습할 수 있어서 음성 분석에서 인기가 많았음
- 그러나 분석과 관련된 중요 특징이 알려지지 않았거나, bias 없는 분석이 필요한 경우에만 유리하고 추출된 latent features를 해석하기 어렵다는 단점이 있음
- supervised learning은 pre-defined features를 사용하기 때문에 해석 가능성이 있지만, biased analysis에 도달할 수도 있음
3. unsupervised learning의 한계와 SqueakOut의 역할
- unsupervised learning에서는 spectrogram에서 vocalization의 latent feature를 학습하려 할 때, 녹음 품질의 변동성이 문제가 됨
- 녹음 조건의 변화는 spectrogram에서 배경 noise 수준과 신호 대 잡음비(SNR)에 큰 차이 불러오고, network 학습에 영향을 미치고 latent feature의 해석을 어렵게 함
- SqueakOut은 정확한 USV segmentation를 제공하여, 녹음 조건의 변동성을 효과적으로 제거
- 결과적으로 생성된 segmentation mask는 unsupervised learning(e.g., Variational Autoencoder) 및 DR 기법(e.g., UMAP, diffusion map)을 활용한 후속 분석에 사용할 수 있음
4. 전통적인 mouse vocalization 분석 방법, CNN vs. SqueakOut
- 전통적으로는 hand-crafted methods를 사용 (vocalization의 duration, frequency modulation, amplitude 등을 수작업으로 정의) → segmentation quality에 크게 의존, 정확하지 않거나 대량의 데이터 처리가 어려움
- 최근에는 CNN이 SL기반의 standard image classification model로 자리 잡고, USV vocalization 분석에 사용되었지만, 시간적, 공간적 측정치(e.g., duration, average frequency)를 제공하지 못함
- SqueakOut은 전통적인 머신러닝 방법(e.g., random forest)과 수작업으로 정의된 특징을 재조명할 수 있으며, 해석 가능한 특징을 사용하여 USV의 다양성을 효율적으로 연구하게 함
4 Materials and methods
Mouse USV dataset
- 공개적으로 이용 가능
SqueakOut architecture
- PyTorch v1.7.0 [39]으로 구현
- https://github.com/gumadeiras/squeakout• Batch Normalization: BatchNorm2d• 드롭아웃: Dropout• 업샘플링: Interpolate
- • Transposed Convolution: ConvTranspose2d
- • 활성화 함수: ReLU6
- • Convolution: Conv2d
Pre-trained SqueakOut network
- SqueakOut 네트워크 구현과 pre-trained weights
- https://github.com/gumadeiras/squeakout
- SqueakOut은 개발, 테스트 환경• NumPy v1.21.5 [51]• PyTorch v1.7.0 [39]• PyTorchLightning v1.4.0 [40]
- • image augmentation library imgaug v0.4.0
- • Torchvision 0.8.0
- • Scikit-Learn v1.0.2 [52]
- • Python 3.7.10
Segmentation metrics
- 픽셀 단위 정확도(pixel-wise accuracy)
- TP = correctly predicting a pixel belongs to a vocalization)
- TN = correctly predicting a pixel belongs to the background
- FP = incorrectly predicting a pixel belongs to a vocalization
- FN = incorrectly predicting a pixel belongs to the background
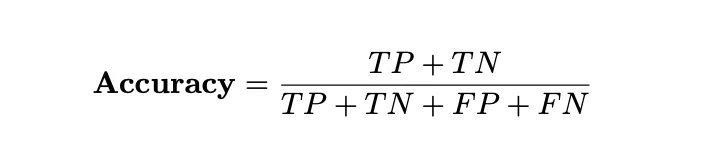
2. Dice score
- 두 집합 간의 겹치는 정도를 측정하는 지표로, segmentation 결과의 품질을 의미